For a paper we recently submitted (Improving FLAIR SAR efficiency at 7T by adaptive tailoring of adiabatic pulse power using deep convolutional neural networks – pre-print here: https://arxiv.org/abs/1911.08118 and published article here: https://doi.org/10.1002/mrm.28590) I was wondering if we can do more than just provide the source code. One problem I often see is that some people have trouble setting up the environments and executing the code, especially when it involves Tensorflow, and it often takes a few emails back and forth before things are running smoothly. Containers do help to a certain extend, but don’t solve all problems. Another problem is that not everyone has a GPU available for running Deep Learning Training algorithms or prediction workloads and often results differ when running on a CPU vs GPU (e.g. 3D convolutions in older versions of Tensorflow crash on a CPU).
How good would it be to just open a fully configured environment in the browser and start playing? Looking at options out there, one finds things like binder, code ocean, or google colab.
Google Colab stood out as working really well for the application I had in mind, but one problem quickly surfaced as it is not possible to package data easily into the notebook. One solution is using the storage provided by the open science foundation.
So this is how the current version looks like: The OSF repository contains the training data, the tensorflow checkpoint to reproduce the results from the paper and a link to the google colab notebook.
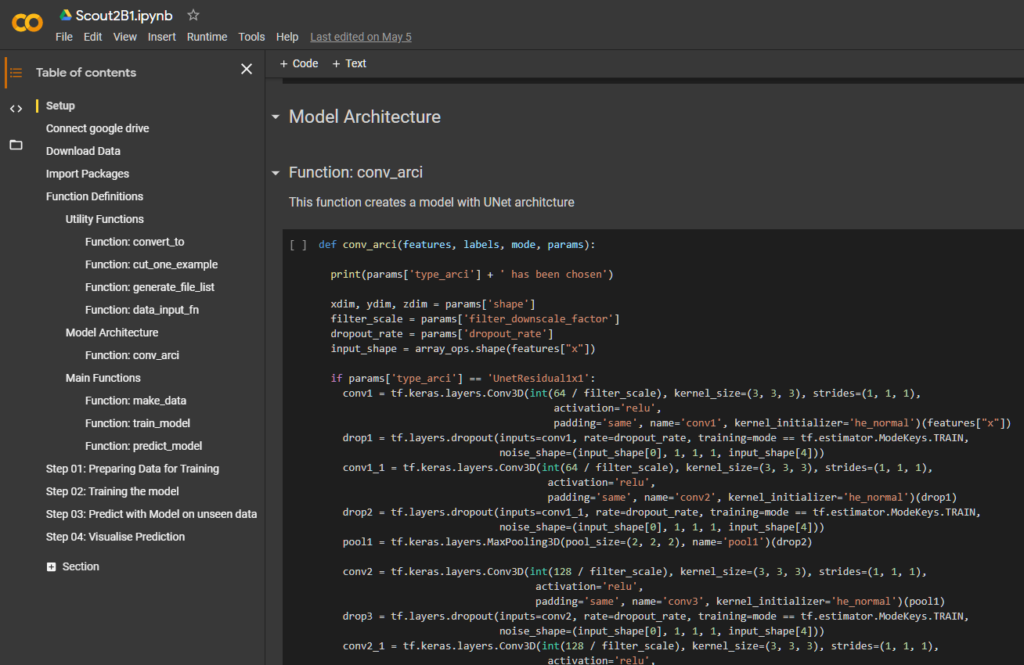
In the notebook we download the OSF files to the google colab VM using the command line interface provided by the OSFclient project:
!osf -p y5cq9 clone .There seems to be a bug in the command line client that breaks the clone command if the github add-on is activated as well, so in case this step fails try to deactivate the github add-on in OSF.
Also uploading the initial training data was very convenient using the CLI:
pip install osfclient
osf init
osf upload -r . .When the training is done we store the results in the users google drive:
from google.colab import drive
import os
google_drive_dir = '/content/drive/My Drive/scout2B1'
drive.mount('/content/drive')
if not os.path.isdir(google_drive_dir):
os.mkdir(google_drive_dir)
os.chdir(google_drive_dir)What do people think about this? Is this easy enough and useful? What are others using to share results and analysis pipelines with readers? Let me know in the comments 🙂

0 Comments